Large Language Models heben organisationsweite Suche auf ein neues Level
Seit dem aktuellen KI-Hype wird viel über Foundation Models, Large Language Models und generative KI gesprochen. Wir wollen diese Begriffe zunächst im Kontext der organisationsweiten Informationssuche einordnen. Welchen Mehrwert bieten diese Technologien für die tägliche Arbeit in Unternehmen und Behörden? Spielt es eine Rolle, ob die Daten in der organisationseigenen IT-Infrastruktur oder in der Cloud gespeichert sind? Bestehen beim Einsatz von LLMs in Unternehmen Risiken? Für welche konkreten Anwendungsfälle ist der Einsatz von LLMs sinnvoll?
KI-Technologien werden schon seit einiger Zeit in moderner Suchsoftware eingesetzt. Wir tun dies in unserer Software iFinder bereits seit 15 Jahren. Mit den neuen Large Language Models, also auf umfangreichen Textdaten trainierten großen Sprachmodellen, eröffnen sich neue Möglichkeiten zur Beantwortung von Fragen in natürlicher Sprache und zur Weiterentwicklung der Suchfunktion.
Auf einen Blick:
- Zur Einordnung: Relevante KI-Begriffe im Kontext der Enterprise Suche
- Risiken und Chancen von LLMs
- Sprachmodelle in der organisationsweiten Suche ohne Risiko einsetzen
3.1. Zusammenfassung und Antworten
3.2. Datenanreicherung
3.3. Keywordsuche und Semantische Suche kombiniert - Enterprise Search mit LLMs in der Praxis – Beispiele für mehr Effizienz
1. Zur Einordnung: Relevante KI-Begriffe im Kontext der Enterprise Suche
Um ein gemeinsames Verständnis zu schaffen, möchte ich zunächst einige für die Suche relevante Begriffe aus der Welt der künstlichen Intelligenz erläutern.
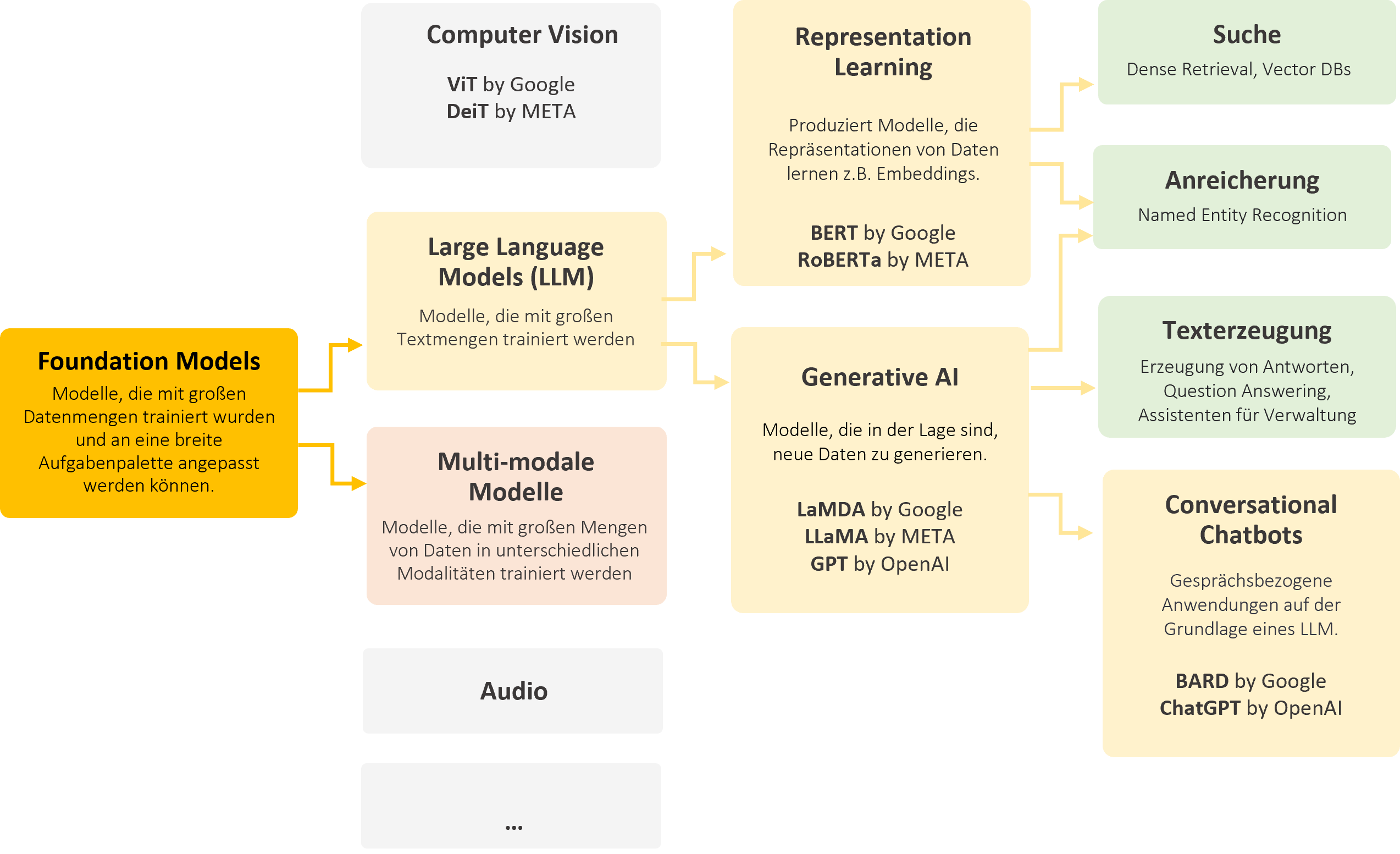
Foundation Models
sind Modelle, die auf Basis großer Datenmengen trainiert wurden und für spezialisierte Aufgaben angepasst werden können. Dieser Prozess wird oft als Fine-Tuning und das gesamte Verfahren als Transfer Learning bezeichnet. Foundation Models können unterschiedliche Datenmodalitäten verarbeiten; die ersten Modelle dieser Art entstanden in der Bildverarbeitung.
Large Language Models (LLMs)
sind eine Untergruppe der Foundation Models, die mit Hilfe von Textdaten speziell auf Sprachverarbeitung trainiert wurden.
BERT-ähnliche Modelle
können Repräsentationen von Texten (Embeddings von Datenpunkten) lernen. Diese spielen beispielsweise eine große Rolle bei der Suche mithilfe von Vektor-Datenbanken. Im Kontext der Enterprise Suche spielen BERT-Modelle eine große Rolle beim Retrieval, also der Suche an sich. Ein anderer wichtiger Anwendungsfall ist die Anreicherung für die Extraktion von Entitäten.
Generative Modelle
sind in der Lage, neue Daten zu erzeugen. Diese neuen Daten sind von den statistischen Merkmalen her idealerweise nicht zu unterscheiden von Datenpunkten des Trainingsdatensatzes. Ein prominentes Beispiel ist ChatGPT von OpenAI, ein conversational Chatbot, der auf generativen Modellen basiert oder auch LaMDA von Google. Zudem gibt es gute Open Source-Modelle. Diese generativen KI-Modelle sind im Rahmen der Suche vor allem für die Erzeugung von Antworten auf Basis von Treffern relevant; wir können sie aber auch für die Anreicherung von Daten benutzen, also das Hinzufügen von (Meta)-Daten zu einem Unternehmensdatensatz, um sie beispielsweise nach Themen zu klassifizieren.
Schaubild: Relevante KI-Begriffe im Kontext der Enterprise Suche
2. Risiken und Chancen von LLMs
Wie bei vielen technologischen Fortschritten bergen LLMs sowohl Chancen als auch Risiken. Zu den Risiken gehören die Generierung von Falschinformationen, Datenschutzprobleme und das Risiko der Verletzung des geistigen Eigentums. So kann es passieren, dass Datenpunkte des Trainingsdatensatzes vom Modell “auswendig” gelernt werden und ein daraus abgeleitetes System deshalb gegen Datenschutzrichtlinien verstößt oder geistiges Eigentum unrechtmäßig wiedergibt oder schlicht und einfach Dinge aus dem Modell heraus erfindet, also halluziniert.
Auf der anderen Seite können LLMs die Benutzererfahrung von Softwaresystemen und Maschinen drastisch verbessern, da sie eine intuitivere, menschlichere Mensch-Maschine-Interaktion ermöglichen, z.B. Antworten auf Fragen liefern anstelle einer Liste von Dokumenten mit passenden Treffern. Zuletzt können moderne KI-Systeme bei der Automatisierung und Rationalisierung von textbezogenen Aufgaben gerade in Zeiten demographischer Herausforderungen Abhilfe schaffen. Das gilt für sowohl für die Rezeption als auch für die Produktion von Texten.
Falschinformationen und Einschränkungen bekannter Modelle
Das Tool ChatGPT kann manche Fragen erstaunlich gut beantworten. Zum Beispiel kann es das Jahr der französischen Revolution wiedergeben. Dies ist allerdings gewissermaßen ein Zufall. Generative Modelle wie ChatGPT erzeugen nämlich Text Wort für Wort von links nach rechts, basierend auf einem vorhandenen Text – dem Prompt (einer „Arbeitsanweisung“) - und dem bisher bereits erzeugten Text. Die Modelle haben dabei kein Verständnis des Inhaltes im menschlichen Sinne, sondern reproduzieren gelernte Muster aus massiven Textmengen, die sie zur Trainingszeit gesichtet haben.
Dies kann dazu führen, dass die Modelle falsche Informationen erzeugen, die wie echte Informationen klingen. Diese Fehler sind unvermeidlich und für den Benutzer schwer zu erkennen. Daher eignen sich diese Modelle nicht zur Beantwortung von Faktenfragen.
3. Sprachmodelle in der organisationsweiten Suche ohne Risiko einsetzen
Innerhalb der Suchmaschine dagegen bietet die Verwendung von LLMs wesentliche Vorteile hinsichtlich Datensicherheit, Urheberrecht und Aktualität. Hier einige Anwendungsbeispiele:
3.1. Von der Suchmaschine zur Antwortmaschine - Zusammenfassung von Dokumenten und Erzeugung von Antworten
Ein idealer Anwendungsfall für den Einsatz generativer KI-Modelle im Rahmen der Unternehmenssuche ist die Weiterverarbeitung von Treffern, z.B. um parallel zur Trefferliste eine Zusammenfassung der gefundenen Textstellen zu generieren. Wir können die generativen Modelle auch benutzen, um mit Suchergebnissen in eine Art Dialog zu treten, also Fragen zu stellen und Antworten zu erhalten. Das Risiko einer Falschinformation, wie man es bei ChatGPT gesehen hat, wird durch diese Herangehensweise massiv reduziert. Denn das generative Modell arbeitet mit den Treffern aus den organisationseigenen Daten, die faktisch korrekt sind, und es hat die Aufgabe, diese Informationen zusammenzufassen.
Wir bauen hier auf eine moderne Unternehmenssuchmaschine mit den ihr eigenen Vorteilen auf, d.h. die suchende Person bekommt nur die Fakten präsentiert, die sie berechtigt ist zu sehen - ein wichtiger Aspekt bei der Verwendung von LLMs im Unternehmenskontext.
Die Suchmaschine iFinder von IntraFind bringt generative Modelle (wie z.B. Luminous von AlephAlpha) mit und ist in der Lage, dieses Modell auch On-premises, in organisationseigenen Datenzentren, auszuführen. Damit sind die Probleme der Datensicherheit und des Urheberrechts, die wir anfangs bei den Risiken bekannter Modelle erwähnt haben, beseitigt. Der Vorteil: Organisationen müssen kein eigenes Know-how aufbauen und die Ressourcen investieren, um selbst ein Modell zu bauen, zu warten oder zu integrieren. Selbstverständlich ist es aber auf Wunsch möglich, eigene Modelle mitzubringen oder SaaS-LLM-Services wie z.B. Azure OpenAI zu nutzen.
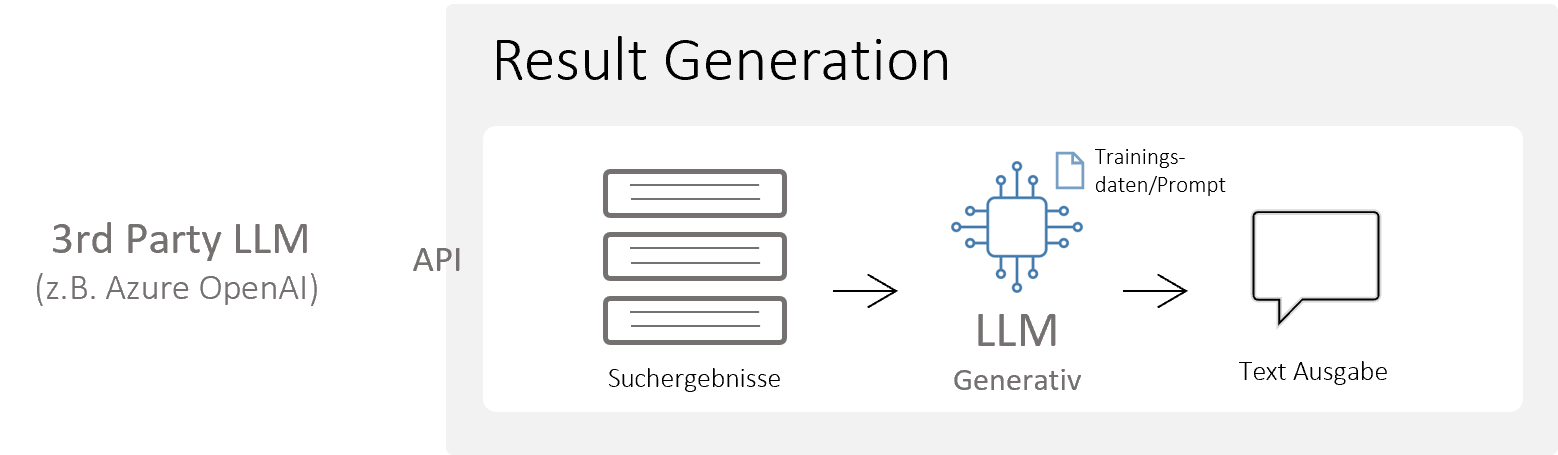
3.2. Datenanreicherung - Optimierte Lösungen für spezifische Anwendungsfälle
Die zweite Möglichkeit für die Erweiterung einer Suchmaschine mit LLMs ist die Anreicherung von Dokumenten mit sogenannten Extraktoren (z.B. zur Extraktion von Entitäten wie Personen, Firmen etc.) für die Klassifikation der Dokumente nach Themen.
Anreicherungsalgorithmen – ob KI-basiert oder nicht - die nur auf der Textebene agieren, haben einen eingeschränkten Zugang zum Informationsobjekt Dokument. Gerade bei Dokumenten, die wir nicht von links oben nach rechts unten lesen, sondern die viele „Inhaltsinseln“ haben, wie z.B. Lieferscheine, Rechnungen oder Formulare, können Extraktoren, die nur auf der Textebene arbeiten, an ihre Grenzen stoßen, da die Reihenfolge des extrahierten Textes oft nicht den semantisch zusammenhängenden Blöcken entspricht.
Hier setzt man sogenannte multimodale Modelle ein, die sowohl Text als auch Layout des Dokuments betrachten. Diese sind in der Lage auch nichtlineare Dokumente präzise zu verarbeiten und bieten somit optimierte Lösungen für spezifische Anwendungsfälle zur Layout-Analyse, optischen Zeichenerkennung (OCR) oder intelligenten Dokumentenverarbeitung (IDP).
3.3 Keywordsuche und semantische Vektorensuche kombiniert - das Beste aus zwei Welten für noch bessere Ergebnisse
Semantische Suche ist kein neuer Begriff, aber wieder in aller Munde. Semantische Suche lässt sich so beschreiben: Die Suchmaschine soll das finden, was ich meine, nicht das, was ich tippe. Es geht also darum Ergebnisse zu erhalten, die der gesuchten Bedeutung entsprechen – auch, wenn man nicht den exakten Begriff eingibt. Hier kommen Sprachmodelle der Sorte Representation Learning zum Einsatz, also solche, die Zahlenvektoren (sogenannte Embeddings) berechnen.
Damit sind wir bei der dritten Möglichkeit, die uns durch die Einbindung moderner Sprachmodelle zur Verfügung steht: die Anreicherung des Suchindex mit Embeddings. Dabei werden die Dokumente analog zur linguistischen Anreicherung bei der Indizierung mittels LLMs angereichert.
Die Suche mit Embeddings (man spricht dabei auch von Dense Retrieval oder Semantic Vector Search) ist ein wirkungsvolles Werkzeug für die Überwindung des sogenannten „Vocabulary Mismatch“ Problems. Dies bedeutet, dass die Suchergebnisse damit relevanter sind, da die Suche Treffer liefert, die der Bedeutung entsprechen, anstatt sich ausschließlich an den eingegebenen Wörtern zu orientieren.
Aber auch die etablierten Suchtechnologien sind sehr weit entwickelt und haben ihre Vorteile. So können Sprachmodelle Begriffe, die sie beim Training nicht gesehen haben und damit nicht kennen, nur sehr bedingt behandeln. Eine traditionelle, lexikalische Suche hingegen kann das hervorragend, ohne trainiert werden zu müssen. Abhängig vom Anwendungsfall sind klassische Suchmethoden somit unter Umständen hilfreicher und der Einsatz generativer KI nicht notwendig. Wenn ich eine Präsentation zu einem bestimmten Projekt suche, möchte ich das Dokument finden und keine durch KI generierte Antwort dazu bekommen.
Der iFinder ist in der Lage beide Suchmethoden zu kombinieren und gleichzeitig zu verwenden. Er bietet also eine Kombination aus klassischer Keywordsuche, erweiterter Linguistik und semantischer Vektorensuche, um optimale Ergebnisse zu erzielen.
4. Enterprise Search mit LLMs in der Praxis – Beispiele für mehr Effizienz
Wenn Organisationen eine Suchmaschine unter Verwendung von LLMs einsetzen, können sie die Effizienz der Arbeitsprozesse steigern, den Informationszugang verbessern und die Qualität der generierten Arbeitsergebnisse erhöhen. Hier einige Beispiele:
- Es lassen sich damit hervorragend prägnante Zusammenfassungen aus organisationseigenem Wissen, z.B. aus umfangreichen Berichten, Präsentationen oder elektronischen Akten komplett mit Quellenangaben erzeugen.
Eine nützliche Anwendung in der öffentlichen Verwaltung ist ein „Vermerkassistent“, der Sachbearbeiter und Sachbearbeiterinnen bei der Erstellung von Vermerken unterstützt. Hierbei liegt der Fokus auf der Erzeugung einer Zusammenfassung des Sachverhalts, während die Beurteilung und die abschließende Empfehlung weiterhin in der Verantwortung der menschlichen Bearbeiter liegen.
- Auch Chats, um aus diesen Inhalten Antworten zu erhalten, sind möglich. Die LLMs in der Suchmaschine arbeiten mit aktuellen Daten, die zur Generierung einer Antwort verwendet werden können, z.B. „Frag das Dokument / frag die E-Akte / frag die Trefferliste“.
- Generell verbessert sich das Thema Frage-Antwort-Systeme (Question-Answering) im Unternehmens-/Behördenkontext enorm – das können sowohl interne organisatorische Anfragen sein, z.B. „Wie melde ich mich krank?“ als auch Chats mit Kunden oder Bürgern.
- So lässt sich der Service von Industrieunternehmen optimieren und für Nutzer komfortabler gestalten. Ein konkreter Anwendungsfall ist der Service-Mitarbeiter, der sich von der KI im Service-Fall schnell Lösungsvorschläge aus der umfangreichen technischen Dokumentation generieren lässt oder eben der Chat für Kunden, der aus Service-Dokumenten gespeist wird.
- Für die automatische Verarbeitung von Dokumenten wie Rechnungen, Lieferscheinen oder Auftragseingängen (Intelligent Document Processing) bieten sich völlig neue Optionen.
- Generell wird das Thema Wissensmanagement auf ein neues Niveau gehoben - mit komfortablerer Anwendung und verbesserten Ergebnissen: Die Suche in Kombination mit generativer KI erleichtert die Einarbeitung neuer Mitarbeiter und sie macht das Wissen ausgeschiedener Mitarbeiter zugänglich. Denn Mitarbeiter erhalten Antworten aus dem kuratierten Unternehmenswissen.
Dies sind lediglich einige Beispiele aus zahlreichen Anwendungsfeldern. Tatsächlich eröffnen sich vielfältige praktische Möglichkeiten für Unternehmen und Behörden. Organisationen kennen ihre Prozesse selbst am besten und haben eine Vorstellung davon, an welcher Stelle sie die KI entlasten und effizienter machen könnte.
Im Kontext der Unternehmenssuche profitieren sie dabei von folgenden Vorteilen:
- Sie behalten die volle Kontrolle über ihre Daten, sei es im On-Premises-Betrieb oder in ihrer eigenen Cloud.
- Darüber hinaus erhalten Sie verlässliche Informationen aus zuverlässigen organisationseigenen Quellen.
Fazit
Mit einer Enterprise Search, die KI-Sprachmodelle integriert, können Unternehmen und die öffentliche Verwaltung das volle Potenzial ihrer Daten ausschöpfen, die effektive Wissenssuche erleichtern und die Produktivität in der gesamten Organisation steigern. Zu den bewährten Skills, relevante Informationen aus großen Datenbeständen vollständig zu finden, kommt die Möglichkeit zur prägnanten Zusammenfassung von Informationen und der Generierung von Antworten aus zuverlässigen organisationseigenen Quellen.
Wie bei allen Projekten, sollte man sich auch vor der Initiierung eines KI-Projekts im Klaren darüber sein, was man mit der KI erreichen will. Wir laden Sie ein, gemeinsam mit uns KI-Innovationen zu verwirklichen und besprechen gern unverbindlich Ihren Anwendungsfall.






