Image


Search engines are essential for our daily digital lives – it has become routine to use the small text field in our private or professional lives, because in times of information overflow, a search engine is vital for navigating the sea of digital information. But what is behind the small text field? How does a search engine find the information we are searching for? These are the questions we would like to address in our new blog series, taking a look into the engine room of a search engine to learn more about its technologies.
In our first blog post, we’ll delve into “natural language processing,” or NLP. Because without natural language processing, a search engine cannot process information to provide appropriate answers to our questions. Language is the key to the world, but only when computers understand us can we fully tap into the world of digital information.
The history of natural language processing began in the 1950s, but at the latest with the introduction of Apple’s Siri in 2011, the topic has reached the wider public. However, only a few years ago, NLP ushered in the revolution predicted by its inventors and changed the way people and computers communicate.
The revolution is urgently needed in our knowledge-based society, with explosive growth in information. Because we need to answer the ever-pressing questions: How do we manage the tsunami of information? How can we organize, structure, and classify information efficiently? NLP provides one answer to these questions, i.e., computers’ processing of natural language. Knowledge can be extracted, recorded, represented, formulated, and processed electronically through various AI models. This enables direct use and the creation of new insights to expand our knowledge.
The various concepts of natural language processing – natural language processing, natural language understanding, and natural language generation – are related, but different:
Natural language processing (NLP) comes from computational linguistics and uses methods from various disciplines such as computer science, artificial intelligence, linguistics, and data science. The goal is to enable computers to process human language in written and spoken form.
Natural language understanding (NLU) is a subfield of NLP and focuses on determining the grammatical structure and meaning of a text. This is important when it comes to, for example, the correct identification of subject and object, the recognition of a process, the relation of a question, or the proper assignment of pronouns. This allows a machine to understand the intended meaning of a text, search engines to answer questions, or intelligent document processing to analyze, classify, and distribute documents.
Natural language generation (NLG) is another subfield of NLP. While NLU focuses on computer reading comprehension, NLG enables computers to generate natural language. NLG also includes text summarization functions that create summaries from documents while preserving the integrity of the information.
We continue to use the generic term NLP in the following text for simplicity.
Human language is complicated, and the process of understanding language is highly complex. Therefore, applying and combining different NLP techniques is common to overcome various challenges. It involves several steps of decomposing human text and speech data to enable computers to extract and process structured data from natural language.
In this article, we would like to provide an overview of the different techniques and methods for natural language processing:
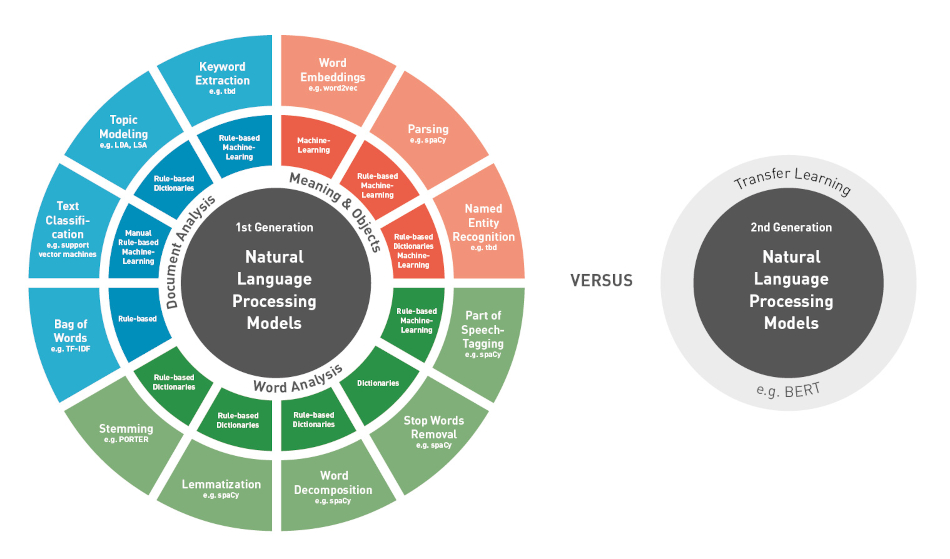
NLP, especially in combination with machine learning, is a broad field that is developing rapidly and will produce many new approaches in the future.
Tokenization is, in simple terms, the division of a phrase, sentence, paragraph, or one or more text documents into smaller units. Each of these smaller units is called a token. These tokens can be anything – a word, a partial word, or even a character.
By analyzing the words in the text, we can apply statistical tools and methods to gain further insight into the text – like the bag-of-words model, which determines and evaluates the frequency of words in a document.
Let’s take a small example from Star Wars with a quote from Han Solo:
You are clear, kid. Now blow this thing and go home!
Women always figure out the truth. Always.

While separating words with a hyphen may seem straightforward, they are often insufficient to perform proper tokenization. It may cause specific tokens to be split incorrectly, such as periods in abbreviations (e.g., Dr.) or an exclamation point in an artist’s name (e.g., P!nk). It can also be problematic when processing complex terms, e.g., medicine, containing many hyphens, brackets, and other punctuation marks.
You can find more information about the topic in the following post The Evolution of Tokenization in NLP — Byte Pair Encoding in NLP, Tokenization Algorithms in Natural Language Processing (NLP) and Word, Subword, and Character-Based Tokenization: Know the Difference.
The words filtered out before the natural language is processed are called stop words. These are frequently occurring words (e.g., articles, prepositions, pronouns, conjunctions, etc.) that do not add much information to the text. Examples of some stop words in English are “you,” “are,” “and,” “an,” and “a.”

The problem with removing stop words is that relevant information can be lost, which changes the context of a sentence. If Han Solo were to say, “You are not clear, kid,” and we were to remove the stop word “not,” the sentence would get an entirely different meaning. The same issue arises, for example, in sentiment analysis. Therefore, it is important to add or remove additional terms from the stop word list, depending on the objective.
In the article Stop Words in NLP, you can find more information and examples. Furthermore, you can find an open-source service for stop words in 54 languages in 22 new stopword languages – 54 in total.
In some languages, mainly German, several words are often put together to form a single term – known as a compound. This makes word decomposition an essential aspect of natural language processing in these languages. In word decomposition, the words are decomposed into their components, e.g., “airplane” into “air” and “plane” or “daydream” into “day” and “dream.”
After all, a search for “book” should also return “schoolbook,” “time” should also find “daytime,” and “football” is a good hit when searching for “ball.”
We cannot solve word separation by algorithmic means alone, because natural language is far too irregular, as in headdress (he-address), longshoreman (long-shore-man), or thinkpiece (thin-k-piece). It is impossible to search for specific letter sequences to identify a word boundary. Therefore, dictionaries with available word parts are essential for meaningful word separation.
Word decomposition plays an important role in the processing of language, for example in the interaction with lemmatization and in semantic-linguistic indexing for better search results.
In stemming, affixes (lexical additions to the root word) are removed by algorithms. For example, suffixes as in “look-ing,” prefixes as in “un-do,” or circumfixes as in “en-light-en” are removed from the verb stem.
In this way, stemming reduces words to their base stem, independent of lexical additions, which is helpful in many applications such as clustering or text classification. Search engines use these techniques to produce better results regardless of word form. Without stemming, a search for “fish” would show no results for “fisherman” or “fishing.”
The Porter stemming algorithm, developed in 1980, has become the quasi-standard for stemming English texts, and modified stemming algorithms are now available for many other languages. They are optimized for the peculiarities and grammatical characteristics of the respective languages.
However, stemming can also lead to unwanted results. Overstemming truncates too many characters, and words with different meanings are reduced to the same form.
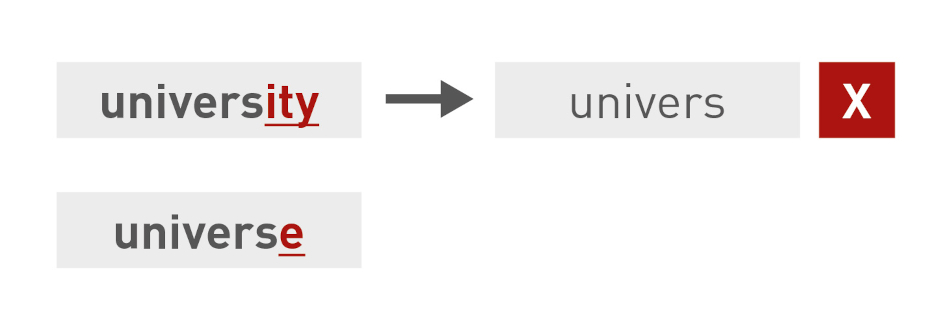
And understemming truncates too few characters, or different word forms with the same root form are treated as different words.
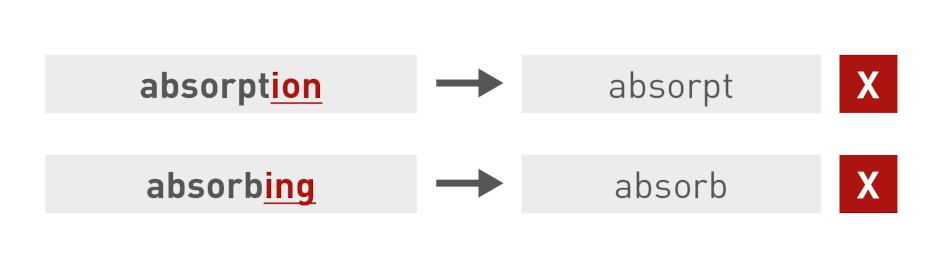
We cannot apply stemming to all languages. Chinese, for example, cannot be stemmed, but the Indo-European languages are more or less suitable.
Even if stemming has some limitations, it is easy to use and runs in an extremely performant way (the algorithm only performs simple operations on a string). If speed and performance are essential in the NLP model, then stemming is undoubtedly the way to go.
For those who want to delve deeper into the specifics of stemming, the article NLP: A quick guide to Stemming provides a good introduction and some illustrative examples.
Lemmatization uses dictionaries (lexical knowledge) in which the algorithm looks up words to resolve them into their dictionary form (known as a lemma). In this way, the algorithm can determine the word stem for irregular verbs or other dependencies to a word stem that are not apparent. Lemmatization can also reduce a word to its basic form and group different forms of the same word.
To clarify, pure stemming cannot be used to reduce the word “better” to the root “good,” or to convert verbs in the past tense to the present tense (e.g., “go” to “went”). Lemmatization easily accomplishes this based on linguistic knowledge. Thus, the NLP model learns that all these words are similar and are used in a similar context.
Lemmatization also considers the context of a word to solve problems such as disambiguation. By specifying a part-of-speech parameter for a word (e.g., whether it is a noun or a verb), it is possible to identify the role of that word in the sentence and eliminate disambiguation. Like the word “drop” as a verb: “Don’t drop your books”; or as a noun: “Enjoy every drop of your drink.”
Even if lemmatization seems to be closely related to stemming, it uses a different approach to identify the root forms of words. A good introduction to the topic is provided by the article State-of-the-art Multilingual Lemmatization.
With part-of-speech tagging (POS), also called grammatical tagging, a word or portion of text is tagged based on its grammatical usage and context.

POS gives each word a part-of-speech tag that defines its function in the example: “Peter” has a PROPN tag, which means that it is a proper noun, and “bought” the VERB tag, which means this is action. The “laptop” and the “Apple Store” are the nouns.
POS tags can be used for various NLP tasks and are extremely useful because they provide linguistic information about how a word is used in a phrase, sentence, or document. POS is handy for distinguishing the meaning of words. For example, it can determine which way the word “row” is used: as a verb, “Lee practices rowing,” or as a noun, “I am sitting in row C.”
Bag of words is a widely used model for counting all words in a sentence and is often used by search engines and for many other NLP tasks, such as text classification. Basically, a frequency matrix is created for the sentence or document, whereby grammar and word order are not considered. These word frequencies or occurrences are used as features for training classifications or labeling a document.
Once again, an example from Star Wars:

However, this approach also has several disadvantages, such as the lack of evaluation of meaning and context. Or the fact that stop words (like “it” or “a”) affect the analysis, and some words are not adequately weighted (the algorithm weights “scoundrel” lower than the word “I”).
One approach to solving this problem is to weight words according to how often they occur in all texts, not just one document. This evaluation approach is called “Term Frequency – Inverse Document Frequency” (TF-IDF) and improves the results by weighting.
With TF-IDF, frequent terms in the text are “rewarded” (like the word “I” in our example), but they are also “penalized” if they frequently occur in other texts. In contrast, this method emphasizes terms that rarely occur in all texts, such as the word “rescue.” Nevertheless, this approach has neither context nor semantics.
An Introduction to Bag-of-Words in NLP and Quick Introduction to Bag-of-Words (BoW) and TF-IDF for Creating Features from Text provide a good introduction and many more examples.
Different NLP methods are usually combined to extract the most frequent keywords from a text. The first step is often to find topics and topic groups that accurately describe a document, and then apply different machine learning algorithms to explore the topics further.
First, the texts are broken down into individual words using tokenization. Afterwards, stop words are filtered, compounds are broken down, and stemming and lemmatization are applied. Then the frequency of the terms in the document is determined using the bag-of-words model. Finally, we weight the terms with TF-IDF – and voilà, the list with the most important keywords is ready. How this works is described in detail in the article Automated Keyword Extraction from Articles using NLP.
Modern versions use machine learning to identify relevant keywords in a document. Some methods use POS tagging combined with heuristics to create words or phrases based on the frequency of occurrence. But there are quite a few other possibilities, as described in the article 10 Popular Keyword Extraction Algorithms in Natural Language Processing.
Text classification places texts into certain predefined categories. Text classification is also called topic, text, or document categorization or classification. There are many approaches to automatic text classification, but they all fall under the following four categories:
Manual
Manual text classification involves human interpretation and categorization of texts. This method can produce good results, but is time-consuming and expensive.
Rule-based
In the rule-based model, texts are categorized using linguistic rules. Texts containing the words “Luke Skywalker” and “Han Solo” would be categorized as “Star Wars.” Again, the craftsmanship of linguists is required to define the linguistic rules. The advantage of rule-based models is that they are easy to understand and can be extended over time. However, this approach also has many disadvantages: they are challenging to implement, and it takes a lot of analysis and testing to create and maintain them.
Machine
The machine variant classifies text based on learned machine learning models. As with NER, this is supervised learning where machine learning models are trained based on preclassified training data. We can use several methods like naive Bayes, support vector machines, or deep-learning-based methods. The challenge in text classification is to “learn” the categorization from a collection of examples for each of these categories to predict categories for new texts.
Hybrid
The fourth approach to text classification is the hybrid approach. Hybrid systems combine the machine-based system with a rule-based system. These hybrid systems can be easily fine-tuned by creating rules for complex classifications that the machine learning model did not correctly identify.
Today, we can use many supervised-learning approaches in natural language processing. As in entity recognition or text classification, trained machine learning models recognize entities or classify texts. However, there is also unsupervised learning where only the texts are present, and categories are found based on similarities.
Topic modeling is a technique of unsupervised learning and can detect hidden semantic structures in a document. All topic models are based on the same assumption: each document consists of a mixture of topics, and a topic consists of a set of words. It means that if these hidden topics are detected, we can infer the meaning of the text.
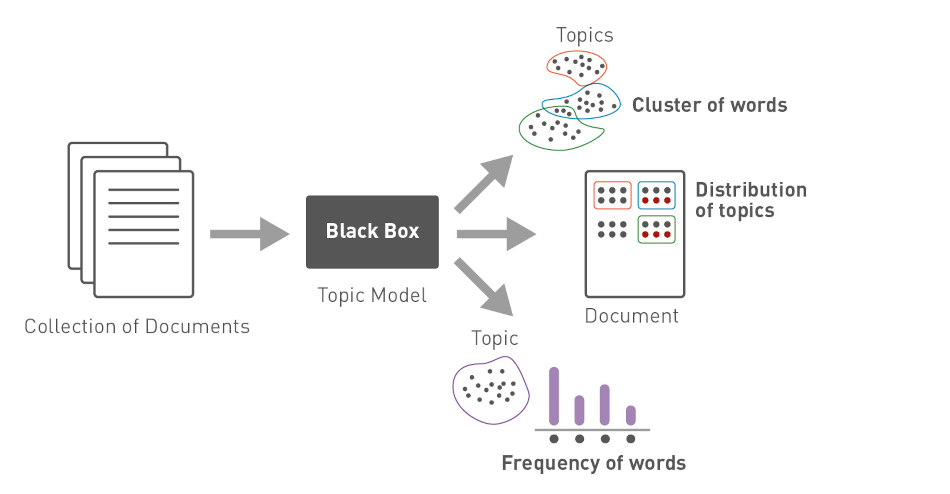
There are several topic modeling algorithms to detect these hidden topics, such as latent Dirichlet allocation (LDA), non-negative matrix factorization (NMF), or latent semantic analysis (LSA). For example, the LDA algorithm identifies groups of related words by assigning a random topic to each word. The algorithm then calculates the probability of whether each word matches a topic and assigns it to the topic if the likelihood is high. The whole process is repeated until the assignment of topics no longer changes.
Named-entity recognition (NER) identifies named entities in a text and assigns them to predefined categories. Entities can be names of people, organizations, places, dates, times, quantities, monetary values, product names, percentages, events, etc.
The main approaches for entity recognition are rule-based recognition, dictionaries, and machine learning.
Dictionaries
The dictionary-based approach stores the named entities in a gazetteer or lexicon list. This approach is quite simple: the only task is to map entities in a list to a text. Moreover, we can quickly create lists from a database (e.g., product names or item numbers), text, the internet, or Wikipedia.
However, dictionaries also have their limitations, such as in recognizing ambiguous terms. For example, the word “Washington” in “President Washington” – based on the context – is the person “George Washington.” However, if the word “Washington” is found in the lexicon as a place (as in “Washington, D.C.”), that entity is classified as a place. This limitation shows that large lists can also miss some important entities, but we can remedy this drawback with appropriate techniques and methods.
Rule-based recognition
The model defines extensive linguistic rules and heuristics for rule-based recognition to recognize certain entities in a text. For example, we can create an admittedly simple rule to recognize people: the words “Mrs.” or “Mr.” are usually followed by additional words for the first and last name, e.g., “Mr. Peter Parker.”
In practice, the rules are mostly quite complex and rely heavily on linguists’ knowledge. We can use dictionaries to recognize entities in documents with little or no context (e.g., Excel sheets with customer data). In this way, rules achieve excellent results in specific domains and defined types of entities – for example, where there is insufficient training material available for machine learning. However, it is difficult to transfer the rules to other application areas.
Machine learning
Another approach is the use of machine learning. There are many methods here, such as the hidden Markov model (HMM) or conditional random fields (CRF). We must manually mark and categorize entities in these supervised-learning methods. Then, we train a machine learning model to predict and classify entities into predefined classes based on statistical correlations – for example, in sentence structure.
The drawback is that this variant requires large amounts of annotated text to train an NER model. The larger the dataset available for training, the better the model built with it will perform. However, unlike rule-based systems, learned models can be more easily used for other use cases.
It is still important to distinguish that recognizing the entity type is not the same as identifying a particular entity. For example, recognizing that Tom Hanks is a person is not the same as recognizing that he is also an actor.
Word embedding is a method of artificial intelligence to calculate the similarity between words. The basic idea of word embedding is that the context of a word is defined by its neighboring words – usually one in a span of two words per direction. Thus, the environment of a word defines the semantics (meaning) and syntax (use in sentence structure) of the word.
Word embedding converts words into a vector. The length of the vector determines how much information about the context of a word is stored. The words that frequently occur together and have a similar meaning also have vectors closer to each other.
With word embedding, the meaning of a word is inferred from its context – quite the opposite of the bag-of-words approach, where words are merely counted.
An excellent example comes from the Süddeutsche Zeitung, a German newspaper (German language). It analyzed all speeches in parliament with the word2vec method, and the algorithm seems to have learned the category “femininity” independently in this way. The vectors “chancellor” and “women” have high values there.
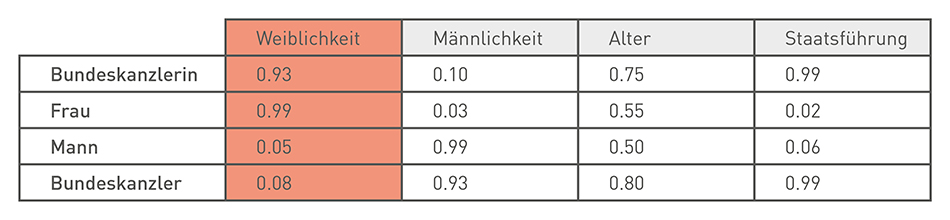
The Embedding Projector of the TensorFlow Library also provides vivid examples. The algorithm seems to have learned that Congress, the Capitol, and the Monument belong to Washington.

Source: https://projector.tensorflow.org/
The disadvantage of word embedding is that you need a huge and as “clean” as possible text corpus to generate a meaningful vector representation. Moreover, identical words with different meanings like “golf” (car, sport) or “bat” (animal, sports equipment) are not supported cleanly because the model maps identical words to the same vector – regardless of their meaning.
If you want to learn even more about word embedding, read the article Why do we use word embeddings in NLP?
With POS tagging, only the word types are tagged, and not the grammatiical relationship of the words within a sentence, to recognize nominal or verbal phrases, for example. This is made possible by what is called "parsing".
Nominal or verbal phrases are groups of words that function as nouns in a sentence. Similarly, a verb phrase is a group of words that function as a verb in a sentence.
A few examples:
Recognizing phrases is important because the meaning of a sentence can only be inferred if we know how these words are put together in a sentence.
In other cases, it helps determine the syntactic function (is it a subject or object, for example) of a word and derives semantic information from it. As in the sentence “Peter bought a new laptop at the Apple Store in Berlin.” – the verbal phrase (VP) “bought” is used to specify the desired action; the nominal phrases (NP) “Peter” and “a new laptop” to define the intent of the action; and pronominal phrases (PP) “at the Apple Store” and “in Berlin” as the subject for the action.

There are three main methods of parsing sentences to recognize phrases:
Syntactic parsing uses rules to break the sentence into subsentences. It converts the sentence into a tree whose leaves contain POS tags (which correspond to words in the sentence). The structure of the tree provides information about how the words are joined together to form the sentence.
Dependency parsing orders the words in a sentence according to their dependencies. One of the words in the sentence acts as the root, and all other words are directly or indirectly connected to this root through their dependencies.
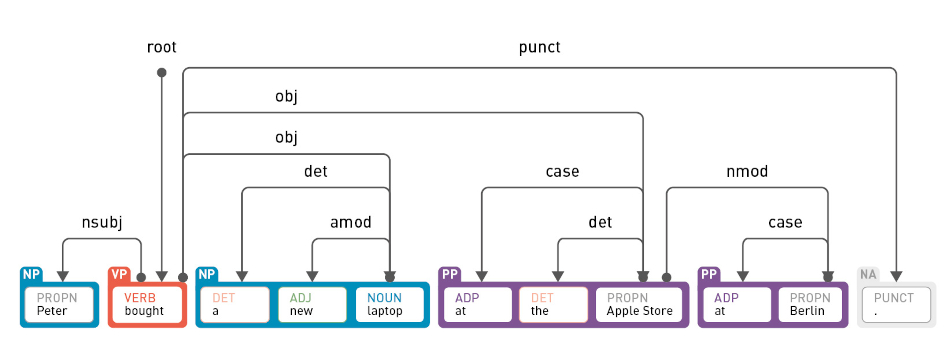
Semantic parsing aims to convert a sentence into a logical, formal representation in order to subsequently process it better, such as:
A simple arithmetic task:
A task to answer a question:
A task for a virtual travel agency:
By combining the different parsers, the structure and meaning of sentences can be recognized. This allows texts to be summarized, classified, or used for question answering, when the aim is to generate an answer to a specific question from various pieces of information.
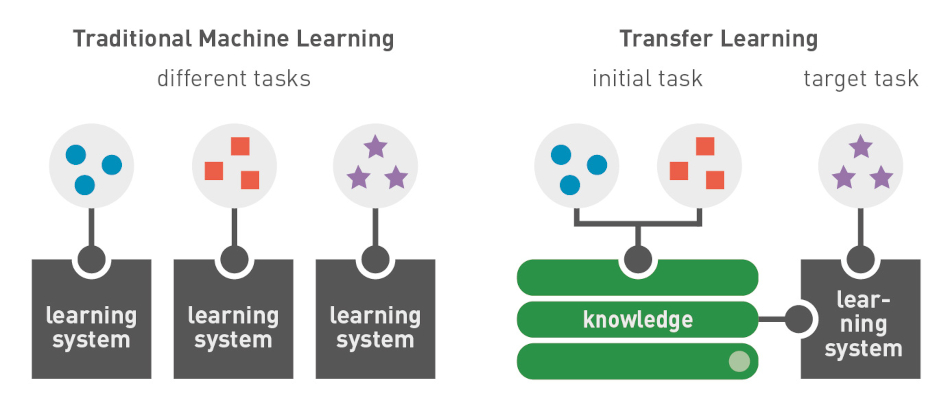
Transfer learning has spawned a new generation of pretrained machine learning models for natural language processing. In contrast to classical machine learning models, which require a large amount of training data, transfer learning models such as GPT, BERT, or ELMos have already been trained and can build on existing prior knowledge.
Thus, transfer learning models can be adapted with new content and adjusted to new specifications faster than classical machine learning models.
A popular transfer learning model, BERT, was first introduced by Google in 2017 and released by Google in 2018 as part of the open-source software BERT. Since October 2019, Google has been using BERT in production searches, and about 10% of all search queries are estimated to be answered thanks to BERT.
Transformers like BERT can understand context and ambiguity in language and resolve disambiguation – which is an important evolution to word embedding. It does this by processing a particular word in the context of all other words in a sentence, rather than processing them individually. By looking at all the surrounding words, the transformer allows the BERT model to understand the entire context of the word.
Specifically, this means that, for example, the word "bank" can be used as a) a financial institution or b) sloping land
I deposit money at the bank.
I pulled the canoe up on the bank.
Word embedding creates one vector for the word “bank.” On the other hand, BERT makes two different vectors because the word “bank” is used in two different contexts. One vector resembles words like money, cash, etc. The other vector would resemble vectors such as water, meadow, lake, etc.
The necessary general “language understanding” was taught to BERT by Google based on extensive training data (such as Wikipedia and the Brown Corpus). This model can now be used for various NLP tasks. The highlight is that BERT builds on what has been learned and can thus be quickly adapted for many scenarios, e.g. for named-entity recognition or for the implementation of a search.
Pretrained transfer learning models can be used to process speech, or we can supplement the models with specific data for a particular task, such as mood analysis and answering questions.
You can learn more about transfer learning and the different models in the article “3 Pre-Trained Model Series to Use for NLP with Transfer Learning.”
More than 80% of all the information we consume daily is unstructured. Therefore, NLP is and will become more and more important when it comes to understanding and finding information. NLP will constantly evolve in the coming years, and we can expect it to influence our lives in more and more areas.




